
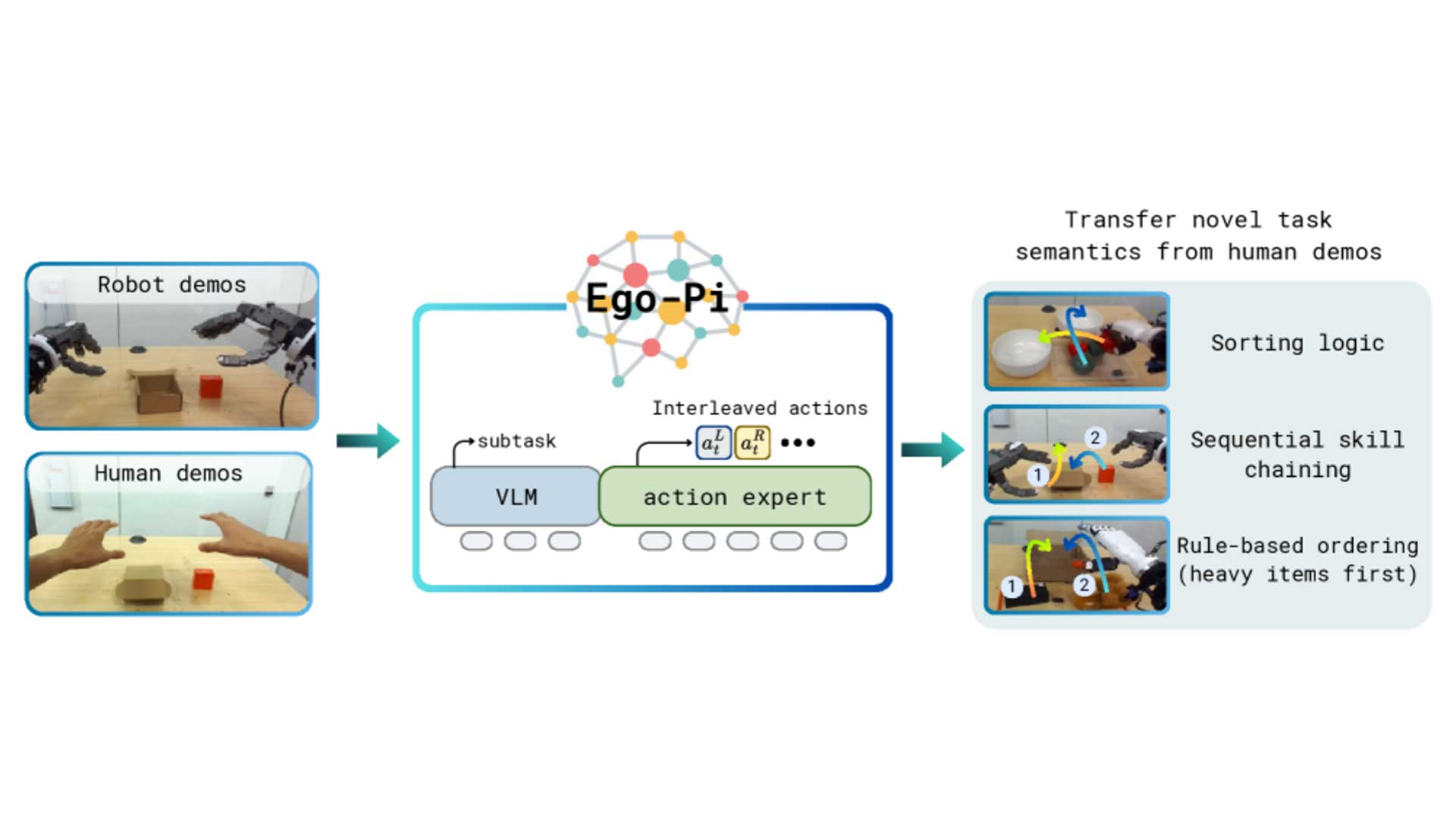
Robot learning is constrained by data scarcity. There is no internet-scale corpus for manipulation, and collecting robot demonstrations requires extensive hardware operating in the physical world. Ego-centric human data is the obvious scalable alternative, but most prior human-robot co-training has used it narrowly, to improve in-distribution performance or to generalize to new scenes while performing the same tasks. The harder question is whether a humanoid can inherit high-level task semantics that appear only inhuman data: the concept of sorting, the composition of existing skills into anew behavior, and rule-based ordering during placement.
This is non-trivial for two reasons. First, most vision-language-action models, including the π0.5 foundation model used here, are built for parallel-jaw grippers with low-dimensional action spaces. A five-finger dexterous hand carries 29 dimensions per hand, 58 for bimanual control, well beyond the model's 32-dimensional action capacity. Second, aligning human and robot action representations is itself unreliable when it depends on inverse kinematics. For a high-degree-of-freedom hand such as the Tesollo (20 active joints), IK and optimization-based retargeting from fingertip targets frequently produce self-colliding or unnatural poses.
The team at Stanford University and Meta built their data pipeline on a Galaxea R1 Pro, with each end-effector fitted with either a Tesollo hand (20 joints) or an Inspire hand (6 joints), and a ZED mini forego-centric vision. For teleoperation, Quest controllers mounted on MANUS gloves drove robot data collection. The Quest controllers track the 6D pose of the operator's wrists relative to the headset, while the MANUS gloves provide the operator's finger joint angles, which are mapped to the robot's hand joints to enable dexterous control. Both devices record at 100 Hz.
The same MANUS glove and Quest controller setup was then used to collect human demonstrations, paired with a table-mounted ZED mini and no wrist cameras. Using one finger-tracking stream for both human and robot collection is what makes cross-embodiment alignment tractable. Rather than predicting fingertip positions and solving inverse kinematics into a robot joint configuration, Ego-Pi adopts a robot-centric action representation: the finger joint angles provided by the MANUS glove mapped per-link into the robot's joint space through per-joint offsets and scaling factors. Because the alignment operates in joint-angle space, it avoids the robot-side IK that tends to produce self-colliding or unnatural poses on high-DOF hands such as the Tesollo.
With consistent action representations in place, Ego-Pi adapts π0.5 through an interleaved action formulation that distributes left and right hand actions across two tokens, preserving the pretrained action head while accommodating 58 dexterous dimensions. Human and robot data were co-trained at a 50/50 batch ratio.
On tasks where the target behavior was never demonstrated on the robot, simple co-training transferred task semantics effectively: 92% success on tomato sorting by color and 90% on rule-based packaging, against 40%and 10% respectively for robot-only baselines. The boxing task, which requires sequencing two skills and is the only bimanual task, needed subtask prediction as an auxiliary loss to reach 93%, up from 27% for simple co-training and 20%for robot-only, and 100% when combined with skeleton overlays. Across all three behaviors the framework reached success rates of 90% or higher.
Ego-Pi shows that human data can do more than reinforce in-distribution behavior. It can teach a dexterous humanoid genuinely novel task structure, including sorting logic, skill chaining, and ordering rules, without a single robot demonstration of the target task. The enabling substrate is a consistent, high-rate finger-kinematics stream shared across both embodiments. As humanoid platforms converge on anthropomorphic hands and ego-centric capture becomes routine, the cost of teaching a new behavior shifts from robot teleoperation time toward far cheaper human demonstration, with the action representation, not the data source, doing the alignment work.








