Dexterous robot manipulation such as unscrewing caps, tool use, and fine finger control is costly to train. Current approaches rely on large volumes of teleoperated robot demonstrations, which are slow and expensive to scale. Meanwhile, humans generate vast amounts of dexterous manipulation data daily, but transferring this knowledge to robots remains challenging.
EgoScale treats large-scale human egocentric video as the primary supervision source and combines it with precise motion alignment through MANUS gloves in a three-stage pipeline.

A Vision-Language-Action (VLA) model is pretrained on 20,854 hours of action-labeled egocentric human videos. Human hand motions are extracted using 21 key points and retargeted into a 22-DoF Sharpa robotic hand joint space, while wrist motion is represented as relative 3D translation and rotation.
The research team uncovers a log-linear scaling law: as human data increases, validation loss decreases predictably and strongly correlates with real-robot performance. This demonstrates that large-scale human video is a scalable and reliable supervision source for dexterous robot learning.

Stage 1 learns a general manipulation prior from unconstrained human data, but it does not match the robot’s sensing and control setup. Stage 2 bridges this embodiment gap.
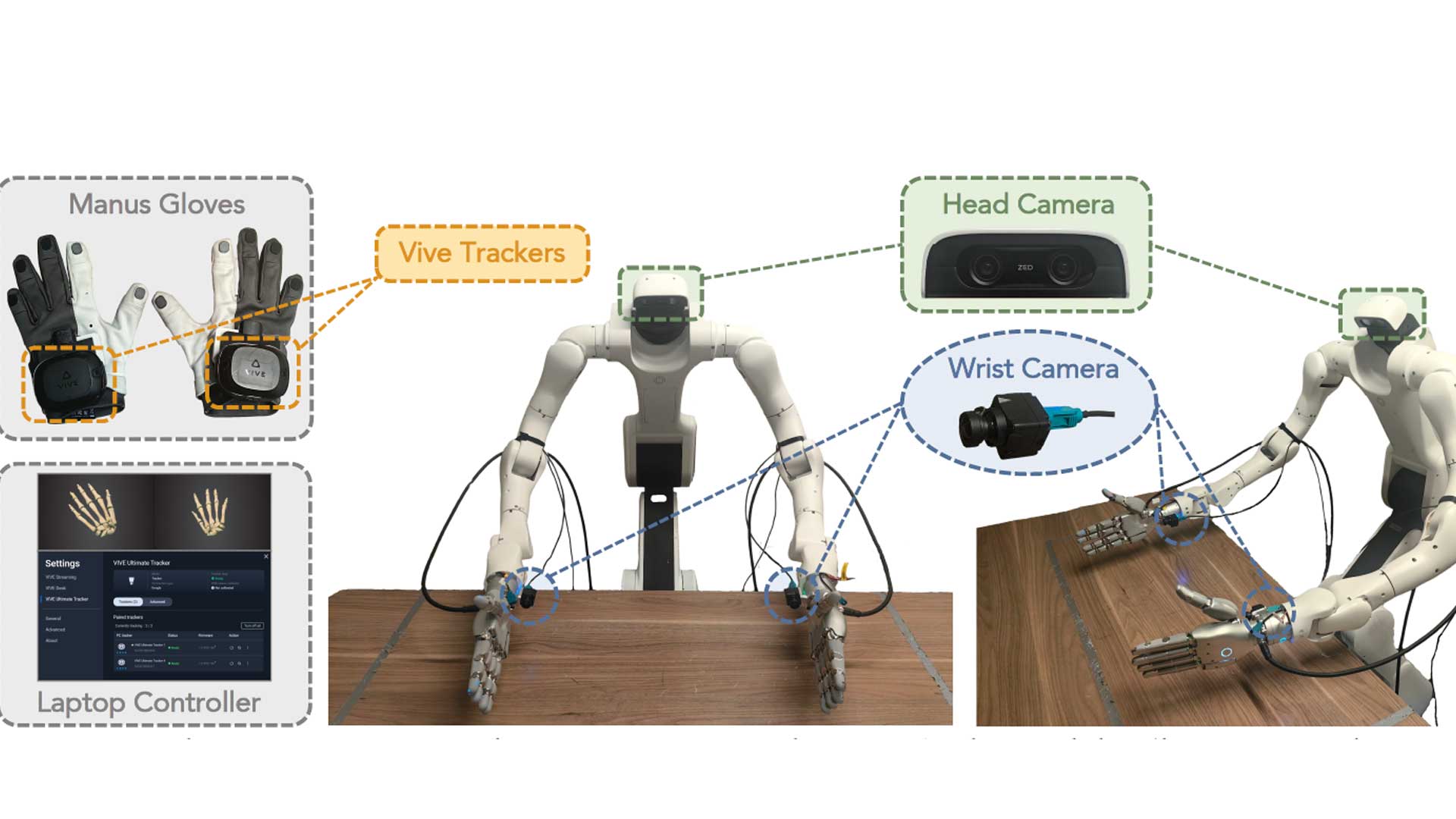
A small, carefully aligned dataset is collected where humans and human-teleoperated robots perform the same 344 tabletop tasks using identical camera setups. During this process, operators wear MANUS gloves to capture high-fidelity finger articulation as 25 joint transforms per hand, while Vive trackers record wrist motion. The same motion-capture setup is used for robot teleoperation, ensuring that human and robot action signals are directly comparable across embodiments.
With approximately 50 hours of aligned human data and 4 hours of robot data, the model anchors human manipulation knowledge into robot control.

At this stage, the model already has a general manipulation prior from Stage 1 and embodiment alignment from Stage 2. Stage 3 fine-tunes it for a specific task.
In the standard setting, about 100 teleoperated robot demonstrations are used to adapt the model to the target task. Because the foundation is strong, this relatively small dataset is sufficient for high performance on complex dexterous tasks.
In the one-shot setting, the model requires only a single robot demonstration, supplemented by aligned human demonstrations, to generalize effectively. This highlights the strong few-shot capability enabled by the earlier stages.
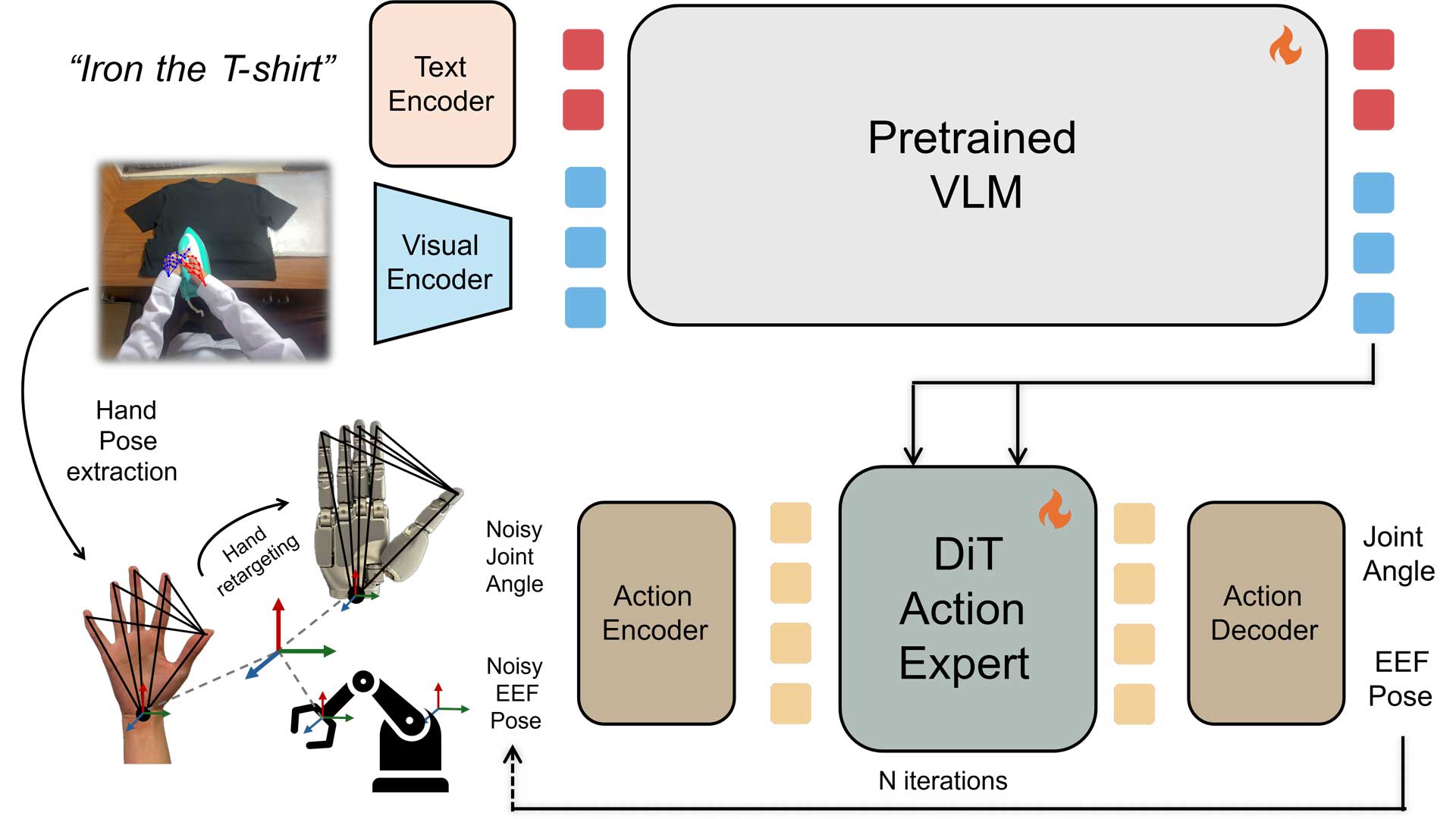
The combination of large-scale human pretraining and MANUS-enabled alignment delivers clear performance gains.
Across five complex dexterous tasks, the full Pretrain and Midtrain model improves average success rate by 54% over a no-pretraining baseline. The Pretrain and Midtrain model also significantly outperforms training from scratch across all individual tasks. In the one-shot setting, a single robot demonstration enables up to 88% success on shirt folding, demonstrating strong few-shot generalization.
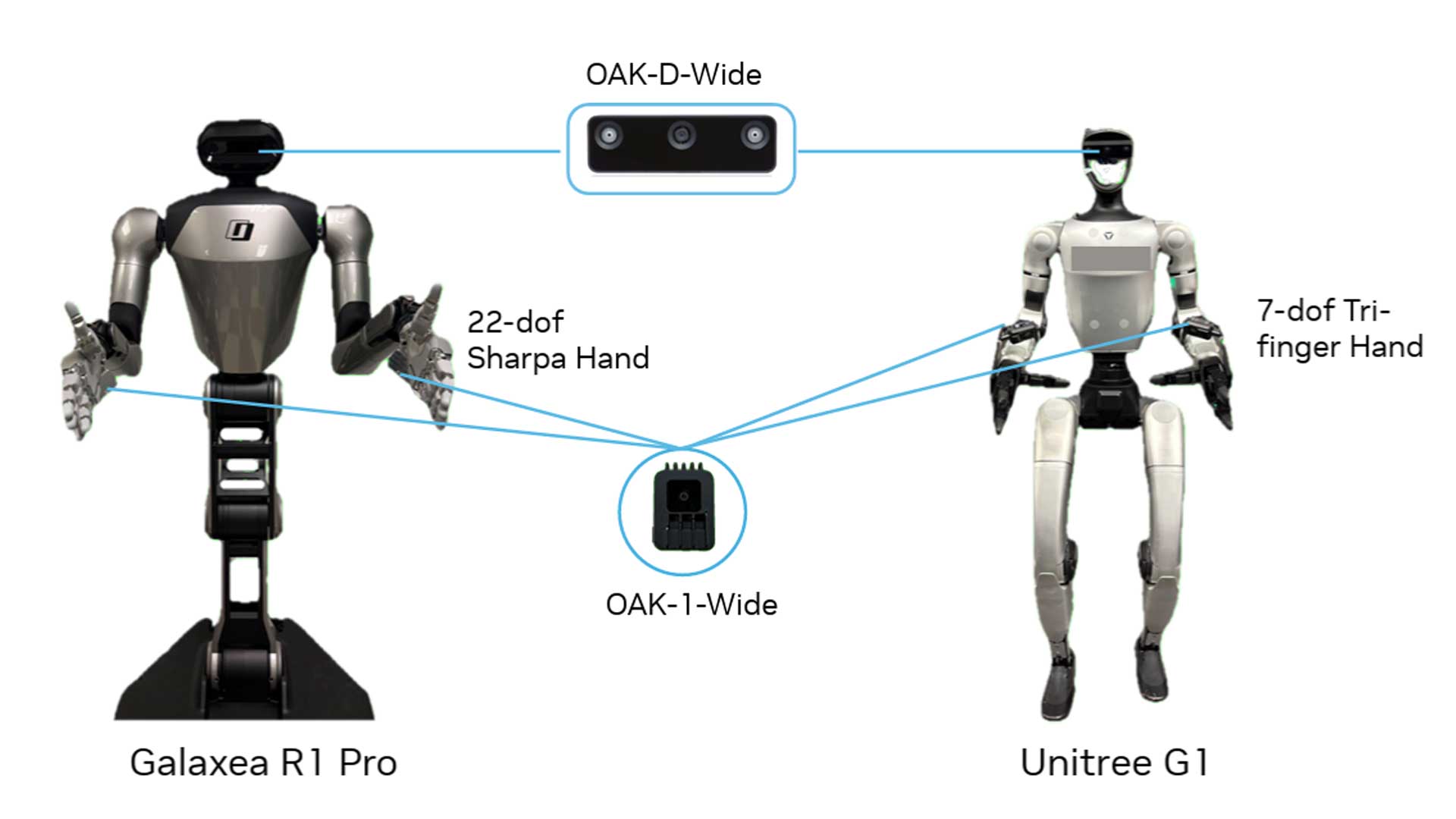
Importantly, the learned manipulation prior transfers across embodiments. Policies pretrained on high-DoF human and dexterous hand data can be adapted to the Unitree G1 with a 7-DoF tri-finger hand, achieving over 30% absolute improvement in success rate and demonstrating that high-DoF human manipulation representations generalize to lower-DoF robot hands.
EgoScale establishes a scalable paradigm for dexterous robot learning:
By acting as the precision action translation layer between human motion and robot joint space, MANUS gloves reduce robot data cost while accelerating deployment of general-purpose dexterous systems.