Training humanoid robots to perform long-horizon, dexterous manipulation tasks requires high-fidelity teleoperation data. While large-scale human video datasets can provide broad motion priors, the critical fine-tuning step depends on robot-specific demonstrations that capture the full complexity of dexterous loco-manipulation.
Conventional VR-based hand tracking is vision-dependent, making it inherently susceptible to occlusion and out-of-view failures. In high-precision manipulation scenarios, these tracking gaps directly degrade data quality and, consequently, model performance.

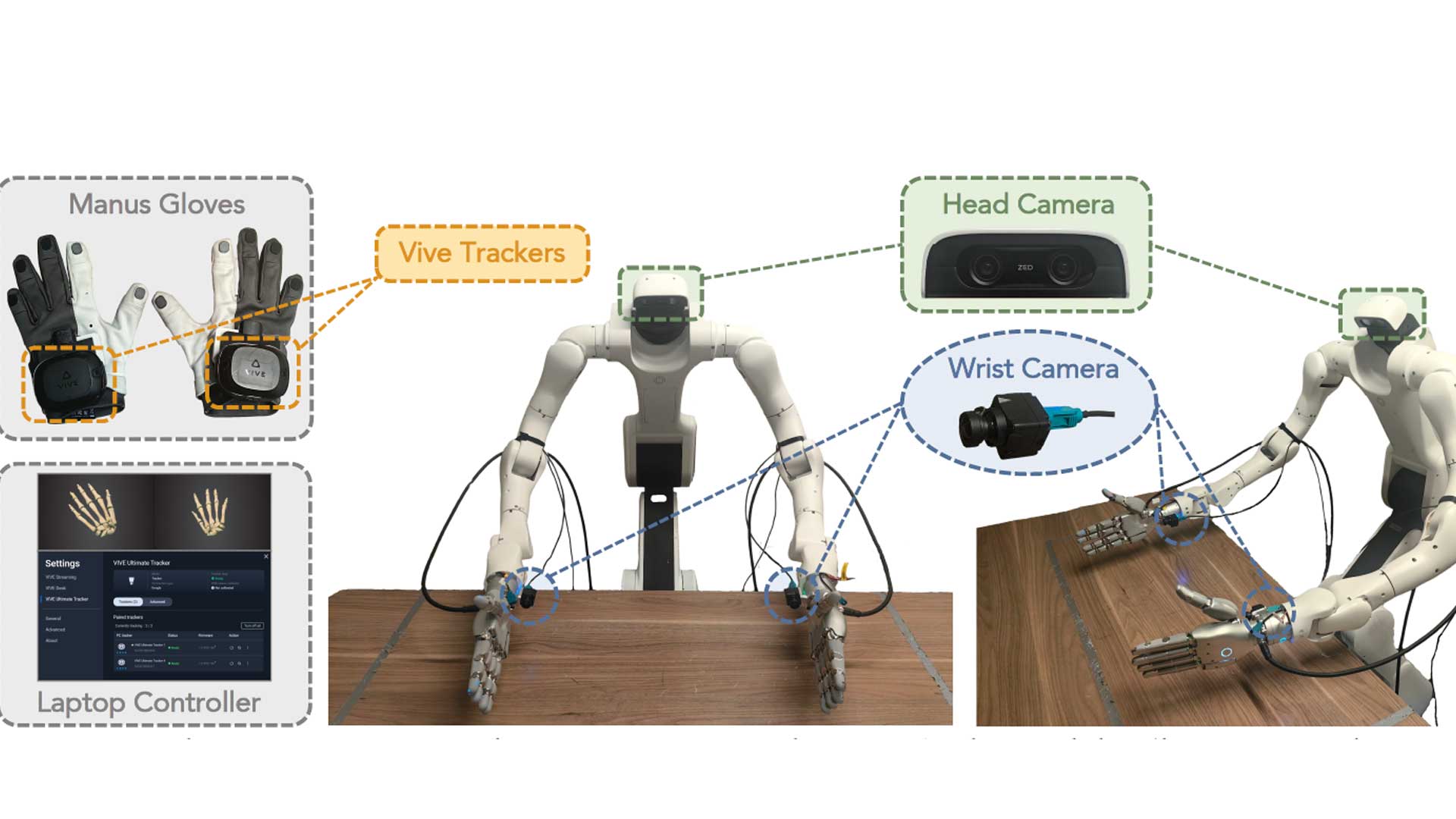
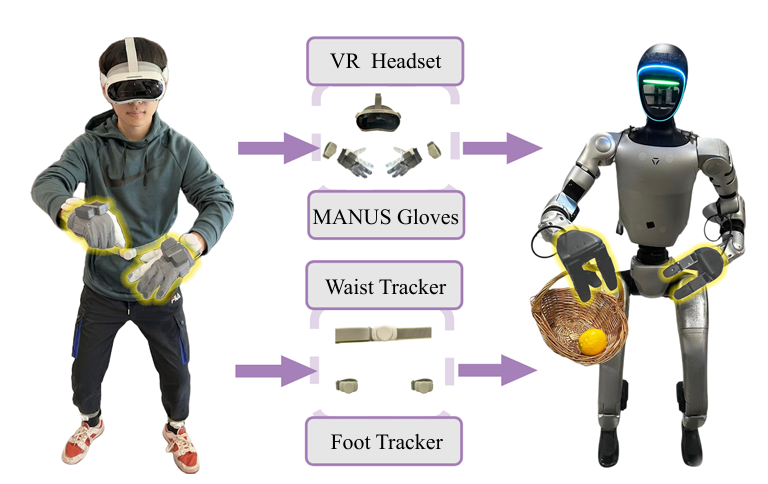
The USC Physical Superintelligence (PSI) Lab built a single-operator whole-body teleoperation framework that deliberately separates three control streams: upper-body pose tracking, dexterous hand control, andlocomotion commands. Each stream is handled by a dedicated sensing modality.
MANUS gloves handle the dexterous hand control stream exclusively. The setup works as follows:
1. A PICO VR headset and wrist trackers capture head and wrist poses, which are fed into a multi-target inverse kinematics solver to compute arm and torso configurations.
2. MANUS gloves capture fine-grained finger motion from the operator, covering all degrees of freedom of the dexterous hand. The thumb, index finger, and middle finger movements are retargeted to the three-finger Dex3-1 dexterous hands mounted on the Unitree G1 humanoid.
3. Waist and foot trackers provide high-level locomotion commands to a reinforcement learning based lower-body controller.
By pairing MANUS gloves with the PICO wrist trackers, the team obtained complete and reliable hand and wrist end-effector poses without depending on vision-based VR hand tracking. As the authors state in the paper:
"This design avoids common occlusion and out-of-view issues and provides more precise hand pose estimation for whole-body dexterous manipulation."
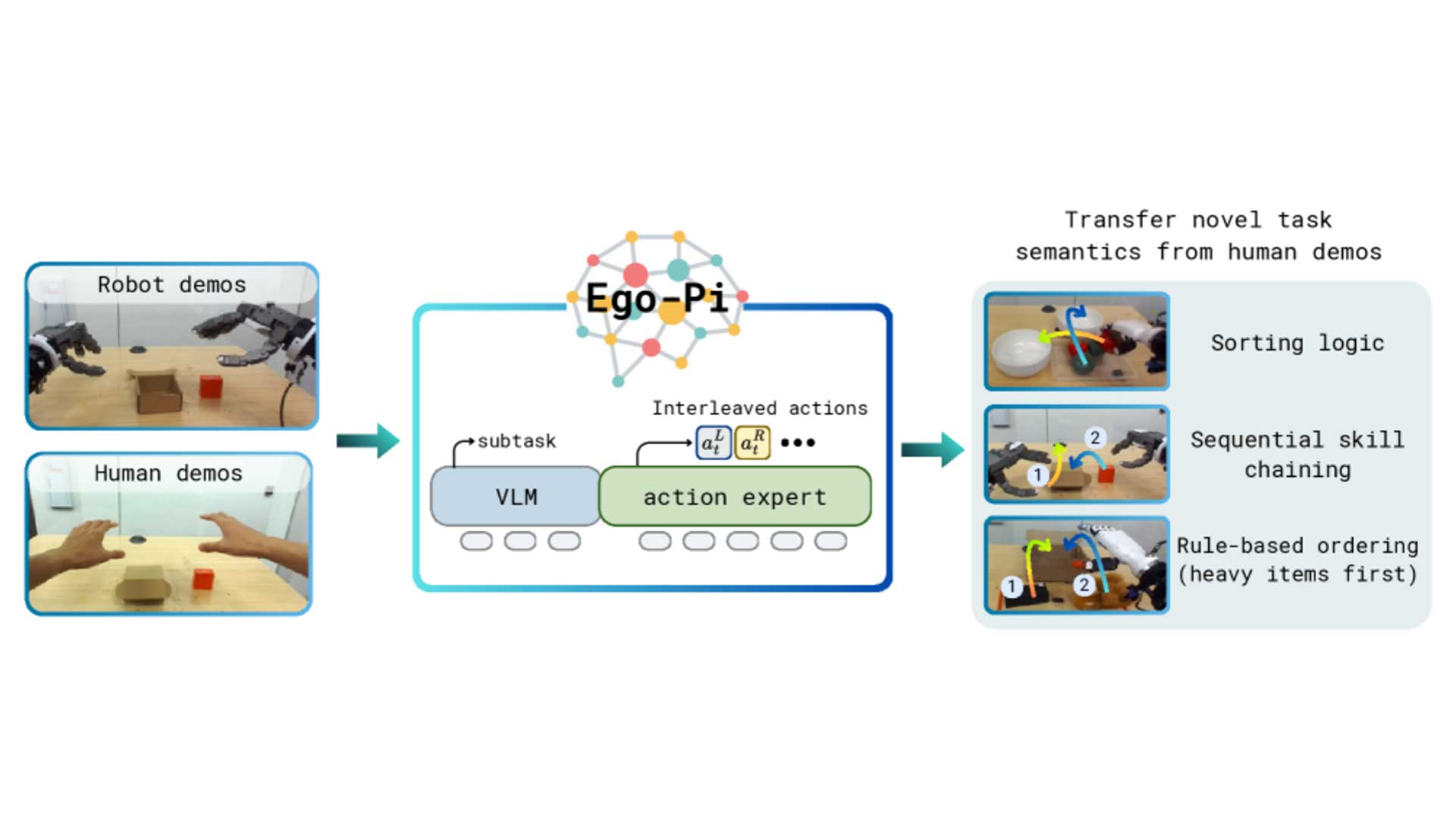
The quality of the in-domain teleoperation data directly determines how well the Ψ₀ action expert fine-tunes to specific tasks. The paper's three-stage training recipe makes this dependency explicit:
1. The VLM backbone is pre-trained on ~829 hours of human egocentric video (EgoDex) to learn broad visual-action representations.
2. A flow-based multimodal diffusion transformer (MM-DiT) action expert is post-trained on the Humanoid Everyday dataset: ~31 hours of real-world humanoid robot data.
3. The action expert is fine-tuned on 80 teleoperated demonstrations per task, collected using the system described above.
Because the third stage relies entirely on the teleoperated dataset, accurate finger tracking at data collection time has a direct upstream effect on manipulation performance at deployment. Tasks such as turning a faucet with a single finger, pulling a tray from a chip can, or stabilizing a bowl during wiping require high precision in hand pose — the kind of accuracy that vision-based tracking cannot consistently provide.
Ψ₀ was evaluated on eight real-world long-horizon loco-manipulation tasks, each comprising three to five sequential sub-tasks involving grasping, pouring, rotating, walking, squatting, carrying, pushing, and pulling. The model outperformed all baselines including GR00T N1.6, π0.5,EgoVLA, H-RDT, Diffusion Policy, and ACT, achieving an average overall success rate more than 40% higher than the second-best baseline, GR00T N1.6, despite using roughly one-tenth of the total training data.
The authors attribute this result to their staged training paradigm and data quality: scaling the right data in the right way, rather than simply accumulating more. The teleoperation pipeline, with MANUS gloves as the finger-tracking layer, is a direct contributor to that data quality.