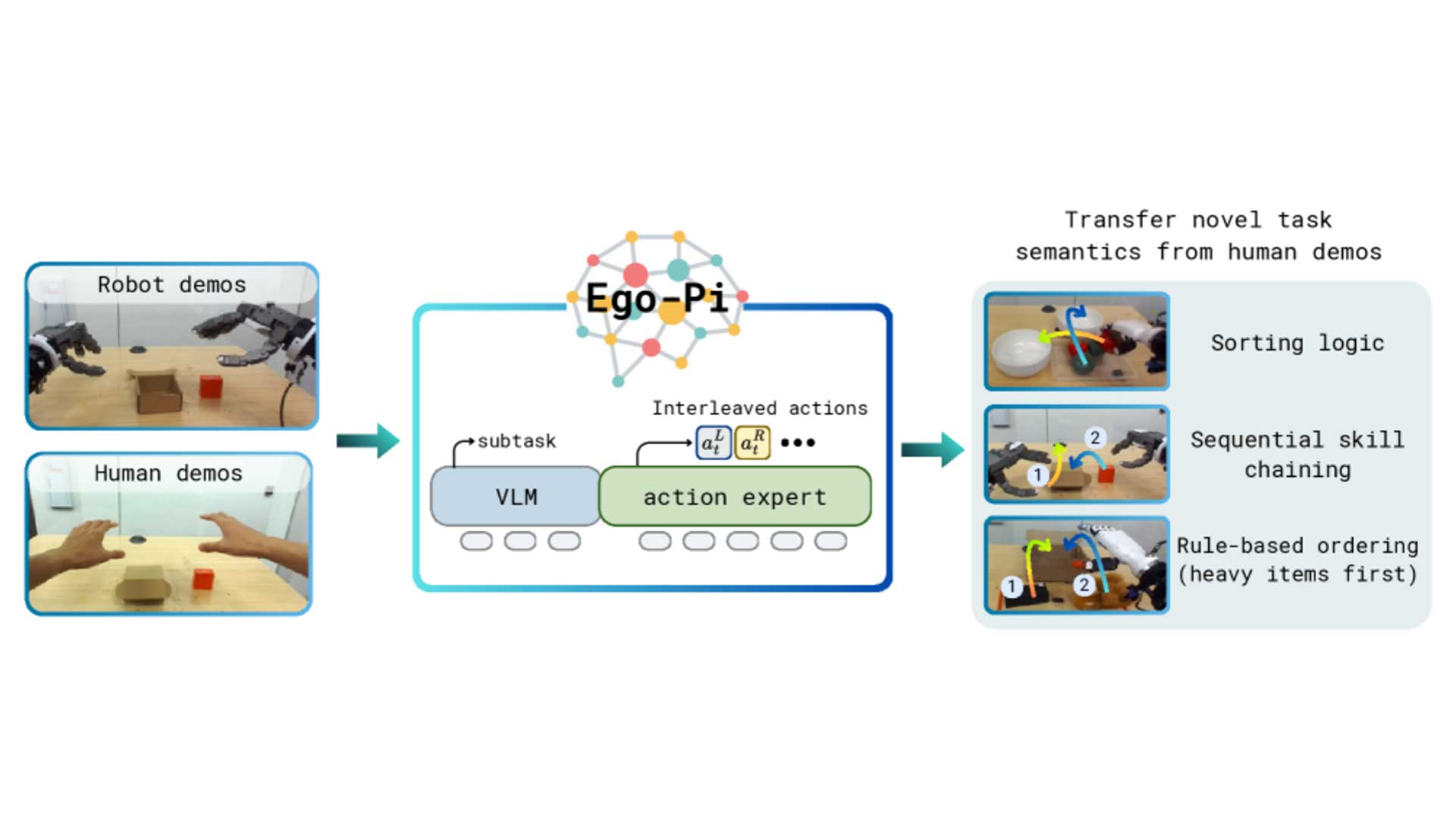
Vision has driven much of the recent progress in robot learning. However, cameras fall short when physical contact, such as inserting a card, turning a key, or handling a deformable object, is involved. Existing VLA models struggle to reason about what happens at the point of contact. Humans continuously adjust their grip through tactile feedback, whereas robots relying primarily on vision largely cannot.
Developed by researchers from UC Berkeley, NVIDIA, and Stanford, T-Rex addresses this challenge by integrating vision, language, and tactile sensing into a unified learning framework. By combining large-scale human pretraining with tactile-grounded mid-training, T-Rex enables robots to react to physical contact rather than relying solely on visual observations. Evaluated across 12 contact-rich manipulation tasks, the framework achieved the highest average success rate among all evaluated methods, outperforming the strongest baseline by more than 30%.
At the core of T-Rex is a 100-hour tactile-synchronized teleoperation dataset spanning more than 200 everyday objects, 22 motor primitives, used to train and evaluate policies on 12real-world manipulation tasks. Building a dataset at this scale required a teleoperation platform capable of synchronizing hand motion, tactile sensing, robot control, and visual observations throughout every demonstration.
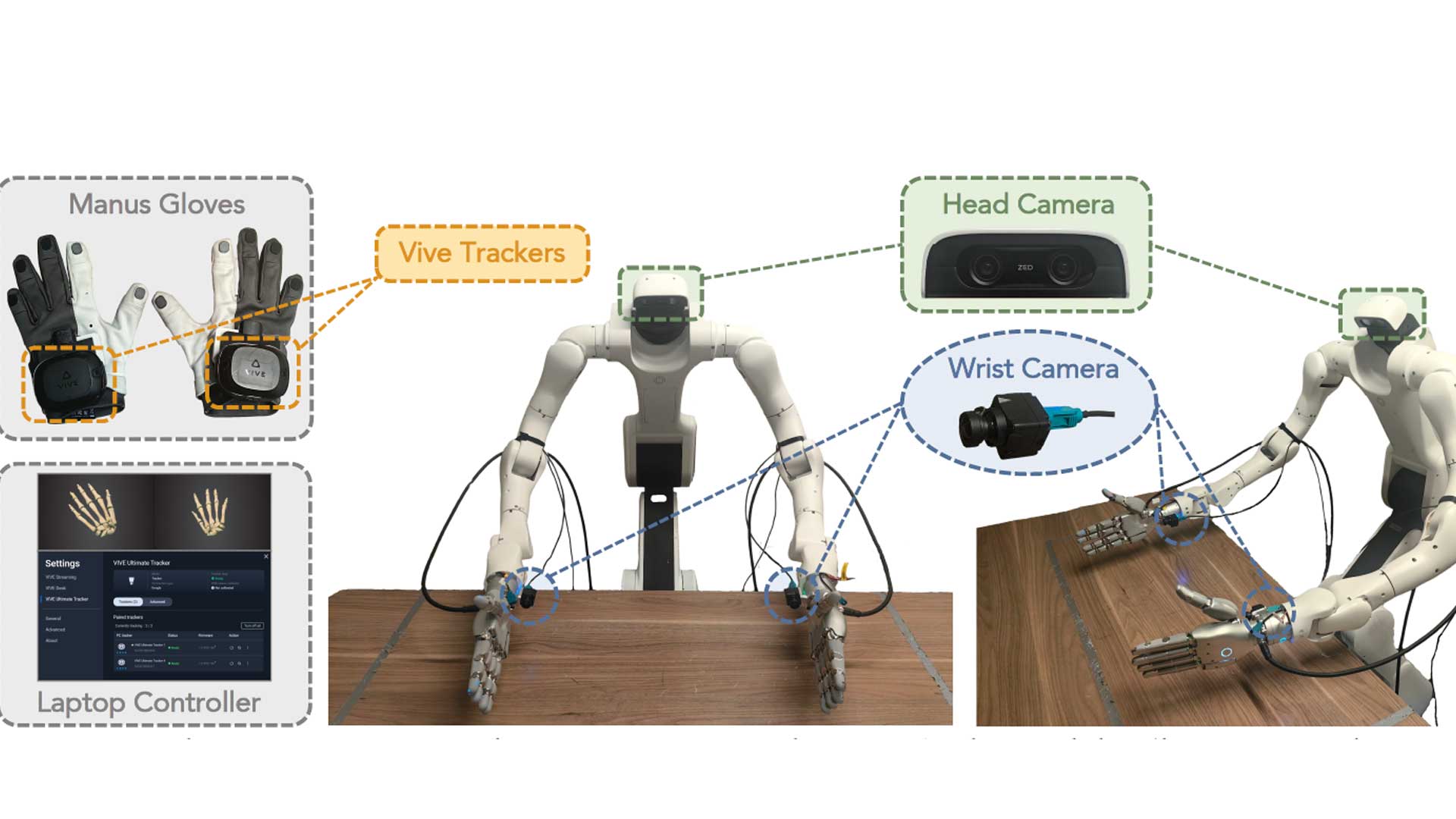
The T-Rex data collection platform combines a dual-arm Dexmate Vega-1 robot with Sharpa Wave dexterous hands, multi-view RGB cameras, and fingertip tactile sensors. Human operators wear MANUS Gloves to capture precise finger motion and VIVE Trackers to capture wrist pose. The recorded motion is retargeted to the robot, enabling natural bimanual teleoperation while synchronizing visual observations, tactile measurements, robot states, robot actions, and natural language instructions into a unified multimodal training dataset.
Contact-rich robot learning depends on demonstrations that faithfully capture how humans manipulate objects. Within the T-Rex data collection workflow, MANUS Gloves provide the finger-level motion capture used to transfer human hand movements to the robot, supporting the collection of high-quality demonstrations for downstream robot learning.
The T-Rex study demonstrates that combining large-scale human pretraining with tactile-grounded robot mid-training improves both data efficiency and generalization. That capability is built on multimodal demonstrations that accurately capture the relationship between human motion, tactile interaction, and robot execution.
T-Rex illustrates how foundation models can extend beyond vision by incorporating tactile information into robot learning. Within the T-Rex project, MANUS Gloves provide the hand motion capture used during teleoperation, supporting a research workflow developed by leading robotics institutions to advance tactile-reactive dexterous manipulation.