Researchers from UC San Diego, Amazon Frontier AI for Robotics (FAR), and UC Berkeley introduce XL-VLA, a vision-language-action framework built around a unified latent action space for cross-embodiment dexterous manipulation. The collaboration brings together robotics and machine learning expertise across three institutions, with Amazon FAR focusing on foundational AI research with long-term real-world impact.
Training dexterous manipulation policies at scale is fundamentally constrained by the heterogeneity of robotic hand hardware. Unlike robot arms, where end-effector interfaces follow broadly common conventions, dexterous hands vary significantly in joint count, actuation architecture, and kinematic structure. The PSYONIC Ability Hand, Inspire Hand, ROBOTERA X-Hand1,and PaXini DexH13, for example, each present different degree-of-freedom counts, mimic joint configurations, and fingertip geometries. This fragmentation means that demonstration data collected for one hand is not transferable to another without manual retargeting, and every new embodiment requires its own dataset and policy from scratch.
The core research question was whether a single vision-language-action (VLA) model could be trained across multiple heterogeneous dexterous hands using a unified action representation, and whether that representation could support zero-shot generalization to previously unseen task-hand combinations. Standard VLA architectures operating in raw joint spaces struggle here because the policy must simultaneously learn to interpret multimodal inputs and navigate hand-specific kinematic differences, without any structural guarantee that similar actions will have similar representations across embodiments.

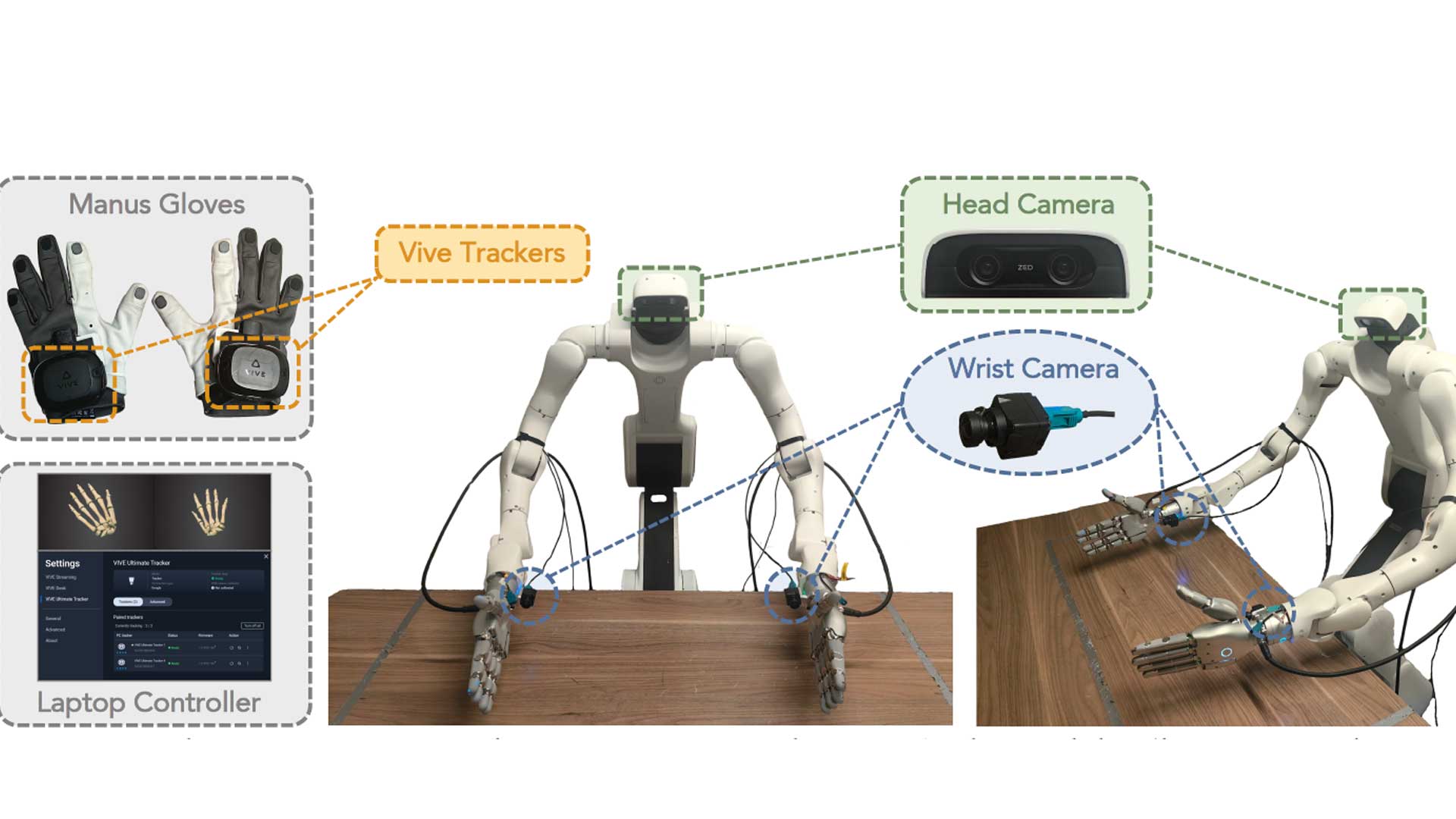
The research team collected demonstrations across two robot platforms: a bimanual tabletop xArm setup and a Unitree G1 humanoid. For the xArm platform, which served as the primary evaluation environment across all four dexterous hands and ten manipulation tasks, data was collected using Apple Vision Pro to track the human teleoperator's hand and wrist poses. For the G1 humanoid platform, a different capture solution was required due to the constraints of upper-body teleoperation in a standing humanoid configuration.
For the Unitree G1 humanoid platform, the team required an upper-body teleoperation system capable of capturing full hand pose during bimanual manipulation tasks. They adapted the HOMIE upper-body teleoperation framework and replaced the original glove hardware with a pair of MANUS gloves to track the human teleoperator's hand pose in real time. The tracked hand and wrist data was then processed through retargeting and inverse kinematics to drive the G1's Inspire Hand at control frequency.
This MANUS-in-the-loop collection pipeline captured demonstrations across four tasks tested on the G1 platform: Prepare Fruits, Hand over Bottle, Pour Sauce, and Pour Sugar. All demonstrations were subsequently encoded into the shared latent action space developed in the XL-VLA framework, where the MANUS-collected trajectories contributed to the same multi-embodiment training corpus as data collected on the tabletop xArm platform. The MANUS glove's compatibility with the HOMIE teleoperation architecture allowed the team to substitute hardware without rebuilding the broader data pipeline, keeping collection methodology consistent across robot platforms.

XL-VLA achieved a mean success rate of 0.825 on the G1 humanoid across four manipulation tasks, compared to 0.525 for the π0 baseline operating in raw action space, a 57% improvement. Across the full cross-embodiment evaluation spanning all four dexterous hands and ten manipulation tasks, XL-VLA raised mean success rate from 0.32 to 0.72, a 40 percentage point gain. Zero-shot generalization experiments, in which the model was evaluated on task-hand combinations withheld from training, demonstrated that the shared latent representation transfers manipulation skills across novel configurations without additional data collection or retargeting. In latent replay experiments, XL-VLA achieved a mean success rate of 0.82 and 0.81 on two cross-hand pairs, substantially outperforming the supervised LAD baseline (0.60 and 0.61) despite requiring no paired cross-hand trajectory labels.
The embodied AI field is adding new dexterous hardware faster than any single lab can collect training data for it. XL-VLA demonstrates that a shared latent action space, pretrained entirely without paired demonstrations and plug-compatible with existing VLA architectures, can substantially close the performance gap caused by embodiment fragmentation. The implication for research infrastructure is direct: high-quality teleoperation data collected today, with precise glove-based hand capture, contributes to policies that generalize to hardware that does not yet exist at time of collection. Teleoperation fidelity at the data collection stage becomes a multiplier on the generalization capability of the downstream policy.